Thank you for visiting this eBook design tutorial. We now have an eBook design startup—
BB eBooks—dedicated to helping
independent authors and
small presses get their eBooks formatted, converted, and ready for sale at all the major online retailers (e.g.
Amazon's Kindle Store,
Barnes & Noble's Nook,
iBookstore,
Smashwords, etc.) Please
contact us for a no-obligation quote. For those writers, editors, and publishers looking to go the DIY route for eBook production (you probably are if you visited this page), we offer
free online tutorials and
apps to help you professionally
design your eBook. Please visit our
Developers page and let’s work together to improve the overall standards of eBooks. Also, please
sign up for the mailing list for promotions, design & marketing tips, plus eBook industry news.
Problematic Formatting on eBooks due to Direct PDF Conversion
Complaints about poor eBook formatting from the big publishing houses are becoming more numerous from readers. You would never see improper page breaks, erroneous fonts, and garbled text on a print book, so why are the publishing houses allowing these sloppy standards into eBooks?
Neal Stephenson’s latest eBook Reamde, a technothriller ironically about a computer hacker, had
random hyphens scattered throughout the Kindle edition. Amazon eventually had to temporarily yank it until HarperCollins got their act together to justify the $14.99 cost.
While not knowing the workflow that happened behind the scenes at HarperCollins, I’m guessing the Reamde flub was the result of poor conversion from a finalized PDF for print into the eBook formats.
Karen Dionne at the Huffington Post highlights the problem in converting PDFs into eBooks:
Self-published authors frequently take the hit for poorly edited and badly formatted e-books. But the truth is, many of them are more careful about proofing their work than traditional publishers seem to be.
"I don't think I've yet seen an e-book that didn't have some pretty blatant formatting and typographical errors in it," says Keith Cronin, author of the novel Me Again, "and I'm talking about even bestselling books from the major publishing houses. In some cases I've also owned the paper version of the book, and have confirmed that the error only appears in the e-book."
Portable Document Format (PDF)
The
PDF was developed in the 1990s by Adobe as way for computer users to
read complex documents in a standardized format—
not edit. Unlike the PDF’s fixed-layout format, MOBI (the eBook format for Amazon) and EPUB (the eBook format for everywhere else)
have reflowable content to accommodate differently-sized eReaders. This means that a PDF cannot be easily changed into eBook formats by any third-party software. Even when a PDF is created from an InDesign layout, which is frequently done in the professional publishing industry, it is not a simple task to convert it back to the source InDesign file. Unfortunately, many publishing houses and authors with backlists only have their final print available in PDF format and not in a word processor format (like Word’s .doc or .rtf). Sucking the information out of a PDF is a challenging task, but here are some tips to make it a bit more manageable. Since this is time-consuming and prone to error, these methods should only be used if you have no access to any other source files (i.e. a Word document, InDesign files, etc.)
Use Acrobat Pro to Save As a Word Document
Acrobat Pro is similar to the free Acrobat Reader offered by Adobe, but the Pro version has a lot more features. Unfortunately, the software is priced at $199 and many writers don’t want to shell that out during these hard times. Assuming you want to go this route, let’s take a look at my PDF version of
How to Format Your eBook for Kindle, NOOK, Smashwords, and Everything Else. The PDF contains a significant number of images, text, bulleted lists, and other complexities. Trying to cut and paste from the PDF will leave a lot of hard breaks and mangle the formatting. You want to make sure that the text is reflowable prior to trying to build an eBook.
Perform the following steps to convert your PDF into a .doc format.
- Open the PDF with Acrobat Pro
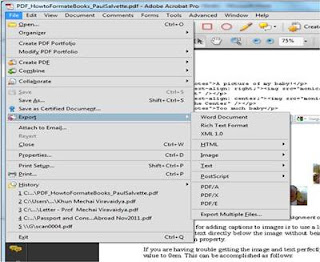
- Select “Export” under the File tab
- Select “Word Document”
- Click on “Settings”
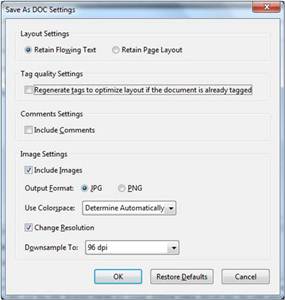
- Ensure that the “Retain Flowing Text” button is checked; otherwise, you will have hard breaks on each line
- Do Not Click the button for “Regenerating tags” or “Including Comments” as this may crash your computer
- Select “Ok”
 |
| Steps 2 and 3 |
 |
| Step 4 |
It may take a while for the conversion to take place and create a valid Word document, but it will eventually finish up.
Alternative Method for Converting PDF to RTF with Calibre (Free)
RTF (Rich Text Format) is similar to the .doc format and can be opened with Microsoft Word and many other word processing programs.
Calibre is an open-source eBook content management system that can do a variety of conversions between formats with an extensive amount of options. The
Calibre manual advises to use a source PDF as a last resort, so this tutorial assumes you have absolutely no other option to make your eBook.
To convert a PDF to RTF perform the following in Calibre:
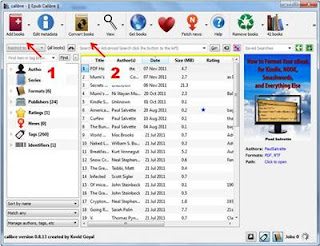
- Click “Add books” on the main page to add your source PDF
- Click “Covert Books”
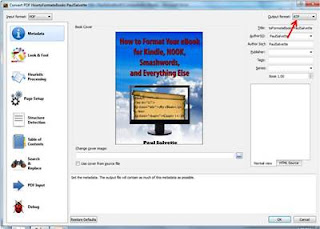
- Select “RTF” under the Output format in the upper right hand corner
- Press “Ok”
 |
| Steps 1 and 2 |
 |
| Step 3 |
Calibre is a great program that is absolutely free, and the conversion results from PDF to editable content are almost exactly the same quality as Acrobat Pro.
Examining Your Converted Content in a Word Processor
This is the ugly and labor-intensive part. You will notice that the editable content that you open in either Microsoft Word or Open Office looks completely terrible. Problems converting from PDF include (but are not limited to):
- Headers and footers from the PDF showing up in the content
- Garbled characters
- Extraneous spaces and indentations
- Content placed into text boxes
- Images located all over the damn place
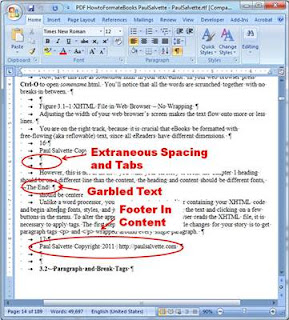 |
| The Ugly Results of PDF Conversion |
To prepare your document to be converted into XHTML as part of the MOBI and EPUB workflow, you really need to spend some time editing this messy content. Look for patterns that became garbled during conversion (e.g. loss of certain capital letters, loss of bulleted lists, etc.) and do your best to rectify the myriad of problems. You can use the Find and Replace feature (Ctrl+H) to help make short work of this task. For the extraneous spacing before and after paragraphs, you can get rid of these with the “
Trim leading and trailing spaces” in a text editor like Notepad++.
This process may sound lousy, but it is better than trying to directly convert to plain text from PDF, because you retain some of the formatting (e.g. italics, headings, etc.) when converting from PDF to .doc or .rtf.
Extracting Images from and RTF or DOC
Hypothetically, you could go image by image and copy and paste to Powerpoint or Photoshop and then save the image. This can be a tedious task if your eBook has an extensive number of images. To extract all images from a document, perform the following steps:
- Save your .doc or .rtf as a .docx file
- Open the .docx file with 7-zip or another unzipping utility
- Look for the folder /word/media
- All images are located in this folder
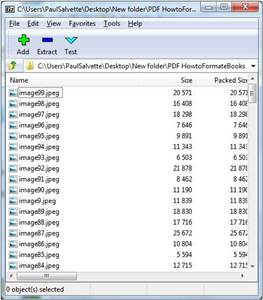 |
| Location of Image Files in the .docx Package |
Once you extract all these images, they will be conveniently numbered based on their location within the document. This will be useful as you construct your eBook with XHTML.
Build Your eBook from the Ground Up
Now that you have a workable source document, you can begin the workflow process from the ground up to ensure a 100% perfect conversion.
A detailed tutorial on how to construct an eBook from a manuscript can be found on this website. The entire process can be very labor intensive if you have a complex eBook. However, if you are a publisher planning on charging $14.99 for a Kindle copy, you should be sure it’s perfect.

How to Prepare a PDF for Conversion into an eBook











